目录
失效说明
该文章所提到的方法均已失效。 另一个方案请看:https://github.com/LyzenX/WeiboDanmuDownloader
声明
文章中涉及到的对微博的操作,均为对微博公开信息的获取和对微博公共api的调用,不存在侵入计算机信息系统、收集用户隐私等行为。
前言
因微博开始清理过去的直播回放,需要保存这些视频。又因为直播通常会与观众产生互动,而观众与主播互动的方式通常是发送弹幕,我们希望在保存直播回放的同时保存这些弹幕。但是,在目前(这篇文章编写的时候)似乎并没有关于微博直播弹幕的任何资料,也没有人发表过对此的研究(至少在主流搜索引擎和计算机类主流网站无法找到),而且目前我能找到的所有微博直播回放的搬运视频,都不包含弹幕。所以我花了一段时间探索了微博弹幕的获取方式,并将经验分享给大家。
准备工作
首先最重要的是要有一台电脑。为什么要特别提出来呢,是因为我认识的绝大多数微博视频搬运工,都是使用手机进行操作的(由下图可知此类视频绝大多数的观众都是在移动端观看的,移动端也有不少流媒体下载工具,比如这个,感谢前辈们使下载视频的门槛变低,让我们能够看到更多有意思的内容。而大多数视频搬运工也是普通观众的一员,他们随手将喜欢的视频传播到另一个网站),所以该文章的目标读者中应该有不少是在移动端阅读的。而我们接下来的操作大多需要在电脑上进行,因此一台电脑是必备的工具。

本文选择的操作系统是 Windows ,因为绝大多数人用的都是该系统,使用 Mac OS 的可能需要自己捣鼓一下。如果会用 Linux 应该就不需要我教了吧
接着,我们需要一个能够抓包的浏览器,谷歌浏览器 Chorme ,微软的 Edge ,甚至系统自带的 Internet Explorer(IE浏览器) 都可以(远古版本除外)。
还有,一个微博账号,最好是小号。如果是自己常用的账号且这个账号对你很重要,请慎用(可能会对账号产生影响,但目前我没有遇到任何问题)。
另外,如果需要深入了解原理,并动手操作的话,可能还需要一些编程知识。但请不要担心,如果你只想了解一下这是怎么做到的,也可以大致浏览一下。文末我为你提供了傻瓜式的工具,无需任何编程知识,只需要按照说明即可获取你想要的东西。请注意你是在xxx.lseng.cc获取的资源,如果是在站外可能会被篡改(p2p下崽器警告)。
代码方面我使用 Java ,版本是 JDK 8。使用其他编程语言也是没有问题的,我们主要使用http request和json相关的库,如果不熟悉你选用的编程语言相关的库,请记得你有一个强大的工具——搜索引擎。举个栗子,假设你使用的编程语言是 Python ,下面说到了需要发送 GET 请求,你就可以搜索 python 发送GET请求。
获取直播回放视频
因为本文主要是获取弹幕,所以对视频的获取的原理不过多赘述。
微博的直播回放采用的是喜闻乐见的 m3u8 格式,所以只要使用任意 m3u8 下载器即可下载视频回放。 这里我以 nilaoda 大佬的 N_m3u8DL-CLI 作为下载工具(github在国内有时候会上不去或者特别慢,如果上不去可以稍后再试)。你也可以选择 这个在线 m3u8 提取工具,无需下载任何软件即可提取视频。
获取 m3u8 链接
如下图所示,建议点击图中所示位置进入到该视频的详情页,避免被其他微博干扰。
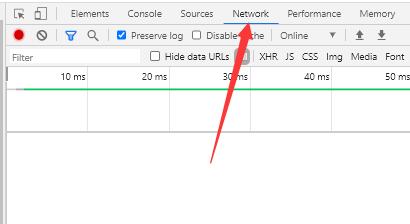
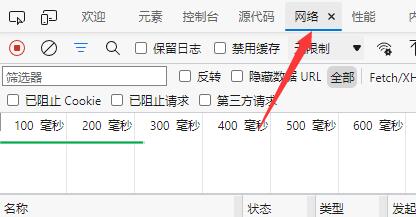
接着我们需要打开 开发人员选项 ,通常是按键盘上的 F12按键 ,或是右键网页某个界面点击检查(或审查元素等)。接着点击 网络(Network),如下图所示。
接着,刷新网页,你就可以看到抓到的文件。 为了方便找到我们要的文件,我们可以“搜索”它。在上图中的 Filter 或 筛选器 ,输入 m3u8 ,下面便会显示出包含 m3u8 的所有数据。点击它,便会显示其的内容,当然,包括它的链接。如图所示。

复制这个链接,然后打开 m3u8 下载器(以 N_m3u8DL-CLI 为例)。请注意,这个 m3u8 下载器的存放地址最好不要出现中文,以防出现问题,比如 D:/Softwares/N_m3u8DL-CLI-2.9.9/N_m3u8DL-CLI_v2.9.9.exe 。盘符名称不影响,比如 D:数据盘 是没有问题的。接着将复制的链接粘贴进去即可。请注意如果是命令符形式,通常不能使用 Ctrl+V ,直接右键即可粘贴。下载完成后,进入到 Downloads 文件夹,就可以看到刚刚下载的视频,最好这时就将其重命名,以防以后忘记这是什么视频或者下载多个视频后分不清。
熟悉之后,便可以 打开视频-F12-F5 一气呵成(提前在筛选器中输入m3u8)。
获取新版微博直播弹幕
还是以 这个视频 为例。
分析
如何鉴别是新版的微博直播弹幕呢,只需要在开发人员选项(F12)的网络(Network)的筛选器(Filter)中输入list,刷新网页,便可以看到抓到的一个数据包。
该包的链接是
https://weibo.com/tv/aj/barrage/list?start_offset=0&mid=4732048030306482
注意中间的tv/aj/barrage/list,它便是新版微博直播弹幕的标志。
我们可以看到请求的参数有start_offset和mid两个,其中start_offset是需要获取的弹幕在视频的起始时间位置,0代表在视频中的00:00:00;mid代表的是要获取的是哪个直播的弹幕,可以理解为唯一标识。
使用浏览器打开该链接,或者在开发人员选项中选中这个包然后点击预览(Preview)或者响应(Response),即可看到请求的内容,它整理过后大概长这样:
{
"code":"100000",
"msg":"succ",
"data":
{
"start_offset":0,
"end_offset":29999,
"list":[
{
"msg_type":1,
"dmid":4732351684545957,
"dmid_str":"4732351684545957",
"content":"\u54c8\u54c8\u54c8\u54c8\u54c8",
"offset":0,
"sender_info":
{
"uid":3490789227,
"user_system":"0"
}
},{
"msg_type":1,
"dmid":4732071547506112,
"dmid_str":"4732071547506112",
"content":"\u65b0\u5e74\u5feb\u4e50",
"offset":0,
"sender_info":
{
"uid":6644378493,
"user_system":"0",
"nickname":"\u5bf9\u51c6\u5706\u5708\u5f00\u67aa\u81ea\u6740",
"avatar":""
}
}
...
]
}
}很明显,这是json格式的数据。
-
最前面的
code为100000表示请求成功,如果是100001表示请求失败。 -
list前的start_offset和end_offset表示这些弹幕数据属于视频中哪一段时间,单位为ms。 如果我们将请求链接中的start_offset改成 0~29999 中的任意值,会发现响应数据的start_offset永远是 0 ,end_offset永远是 29999 。将请求数据的start_offset改为 30000 后,start_offset就会变成 30000 ,end_offset变成 59999 。这说明弹幕以视频每30s封装为一个包,当你播放到视频中任意一个30s区间内,便会读取这30s对应的弹幕数据。你可以在播放视频的时候任意跳转到某个时间(比如跳转到 00:00:12 的某个位置),然后看抓到的数据包,start_offset可以是 12549 ,而不一定是 0、30000、60000等。 -
list为一个数组,里面储存了每一条弹幕的信息。content即为弹幕的内容,我们会发现这是转义的unicode编码,而不是中文。我们可以随意找一个在线unicode转化工具,比如 这个,即可“翻译”出它的内容。 而offset则代表了这个弹幕是在视频中的什么时候出现,由它我们可以确定弹幕出现的时间。 -
sender_info是弹幕发送者的数据,我们可以发现有些有nickname有些没有。但一定会有uid。我们可以通过https://weibo.com/u/$uid$(将$uid$替换为实际的数值)去访问弹幕发送者的微博主页,这样我们就可以知道他是谁了。但是,由于弹幕中有太多人没有 nickname,所以一遍遍去获取他们的名称会消耗大量的资源和时间,而我们将弹幕渲染到视频中的时候通常不需要看到发送者的名称,所以我们索性不管它。
接着我们将请求链接中的start_offset改为30000、60000等,直到响应数据中的code为 10001 时,我们便得到了该视频中的所有弹幕数据。
找到规律后,我们便可以着手编写代码了。
代码
DanMu.java 用来储存单个弹幕的数据
public class DanMu {
public String name; //弹幕发送者名称
public String info; //弹幕内容
public long time; //弹幕发送的时间
public DanMu(String name, String info, long time) {
this.name = name;
this.info = info;
this.time = time;
}
}
HttpUtil.java 用来发送http GET请求,这里使用了apache的commons-httpclient作为依赖
public static String sendGET(String urlStr) throws IOException {
HttpClient httpClient = new HttpClient();
//超时时间为10s
httpClient.getHttpConnectionManager().getParams().setConnectionTimeout(10000);
//GET请求实例对象
GetMethod getMethod = new GetMethod(urlStr);
//设置get请求超时时间为10s
getMethod.getParams().setParameter(HttpMethodParams.SO_TIMEOUT,10000);
//设置请求头
getMethod.addRequestHeader("accept", "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9");
getMethod.addRequestHeader("accept-language", "zh-CN,zh;q=0.9");
getMethod.addRequestHeader("cache-control", "no-cache");
//这里要改成你的cookie
getMethod.addRequestHeader("cookie", "$COOKIE$");
getMethod.addRequestHeader("pragma", "no-cache");
getMethod.addRequestHeader("sec-ch-ua", "\"Chromium\";v=\"88\", \"Google Chrome\";v=\"88\", \";Not A Brand\";v=\"99\"");
getMethod.addRequestHeader("sec-ch-ua-mobile", "?0");
getMethod.addRequestHeader("Upgrade-Insecure-Requests", "1");
getMethod.addRequestHeader("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36");
httpClient.executeMethod(getMethod);
String result = getMethod.getResponseBodyAsString();
//释放http连接
getMethod.releaseConnection();
return result;
}
在访问微博时,通常会先打开一个“微博通行证”,接着再进入微博,这是为了防止你爬取数据。为了获取数据,我们需要模拟登录,而微博判断你是否登录的方法是读取你的Cookie,所以我们需要获取自己的Cookie。
首先,登录你的微博账号并打开微博主页,打开开发人员选项(F12),选择网络(Network),这时候你可能需要刷新一下页面才能抓到包。接着随便点击一个,看看请求头(Request Headers)是否包含Cookie,通常类似于push_count.json的都有Cookie。下图所示这段非常长的内容便是Cookie。

当然,这段Cookie我打了马赛克,为什么要打码呢?
如果你泄露了你的Cookie,别人可能会用你的Cookie来操作你的账号(比如发微博说我是傻狗)。如果不慎泄露,请及时退出并重新登录你的账号,这样会刷新你的Cookie。
另外,Cookie也会随时间推移而自动刷新,所以每过一段时间(可能只有一天),你需要重新获取新的Cookie才能继续操作。
将得到的Cookie粘贴到上面的代码中(替换掉$COOKIE$)。为了方便以后对Cookie的修改,你可以声明一个全局变量或者使用配置文件等。
将unicode翻译为中文
public static String unicodeToCn(String info) {
String[] secs = info.split("\\\\u");
if (secs.length <= 1) {
return info;
}
String res = info;
for (int i = 1; i < secs.length; i++) {
String s = secs[i];
char c = (char) Integer.valueOf(s.substring(0, 4), 16).intValue();
res = res.replaceAll("\\\\u"+s.substring(0, 4), c+"");
}
return res;
}
获取并解析json,将得到的数据存入List中。为了获取所有弹幕,可以递归获取,每次将offset往后移动30000,直到响应数据中的code为10001。
NewDanmuDownloader.java
/**
* @param mid 直播mid
* @param startTimeStamp 直播开始的时间戳(可随便填,不影响最终渲染结果,只影响输出文件每个弹幕发送的现实时间的时间戳)
*/
public static void get(String filepath, String mid, long startTimeStamp){
try {
List<DanMu> result = new ArrayList<>();
next(mid, startTimeStamp, 0, result);
//保存弹幕文件
// DanMuConverter.convertToXML(filepath, result, startTimeStamp);
//result即为最终的弹幕列表,你可以在这里继续添加代码以处理弹幕
//将所有弹幕打印到控制台
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
for(DanMu danmu : result){
System.out.println(simpleDateFormat.format(new Date(danmu.time)) + " " + danmu.name + " : " + danmu.info);
}
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* @param mid 直播mid
* @param startTimeStamp 直播开始的时间戳(可随便填,不影响最终渲染结果,只影响输出文件每个弹幕发送的现实时间的时间戳)
* @param offset
* @param list
* @throws Exception
*/
public static void next(String mid, long startTimeStamp, long offset, List<DanMu> list) throws Exception {
String url = "https://weibo.com/tv/aj/barrage/list?start_offset="+offset+"&mid="+mid;
String origin = HttpUtil.sendGET(url);
System.out.println(origin);
JSONObject root = new JSONObject(origin);
if(root.getInt("code") == 100000){
JSONObject data = root.getJSONObject("data");
JSONArray array = data.getJSONArray("list");
for(Object entry : array){
if(entry instanceof JSONObject){
JSONObject danmuRaw = (JSONObject) entry;
JSONObject senderInfo = danmuRaw.getJSONObject("sender_info");
//获取弹幕发送者名称,实际渲染的时候不包含发送者名称
//如果没有nickname,则直接将其uid作为名称
String name;
if(senderInfo.has("nickname")){
name = senderInfo.getString("nickname");
} else {
name = String.valueOf(senderInfo.getLong("uid"));
}
//弹幕的时间
long dOffset = danmuRaw.getInt("offset");
String content = UnicodeUtil.unicodeToCn(danmuRaw.getString("content"));
//将emoji从html标签抽离出来
// content = replaceEmoji(content);
DanMu danmu = new DanMu(name, content, startTimeStamp + dOffset);
list.add(danmu);
}
}
next(mid, startTimeStamp, offset + 30000, list);
}
}其中处理弹幕中的emoji和保存弹幕文件我暂时注释掉了,这些到后面再讲。
只需要调用get(filepath, mid, startTimeStamp)即可获取所有弹幕并输出到控制台。filepath为保存的位置和文件名,比如"D:/WeiboDanmuDownloader/danmu.xml"。其中mid的获取方式可以看前面分析部分,startTimeStamp为直播开始的时间戳(毫秒),比如上例的直播是在 2022年2月1日 13:00 开始的,其实没必要知道具体的时间,不影响最终渲染结果。
接着我们可以找一个在线时间戳生成网站,比如这个,在“时间”一栏输入2022-02-01 13:00:00,可以看到这个时间对应的时间戳是1643691600000。
控制台输出结果如下:

如果直播回放的时间太长,就会长时间不断向微博获取数据,这有可能导致弹幕数据获取失败甚至你的ip被微博暂时屏蔽。所以,请不要在短时间内频繁获取数据,你也可以声明一个全局变量t记录获取的次数,每获取几次数据就等一小会,比如在next()方法的首行加上
//每获取10次数据暂停3秒钟
if(t % 10 == 0){
Thread.sleep(3000);
}
t++;
以上提供了获取新版微博直播弹幕的方法,如果需要保存弹幕文件并将其渲染到视频中,请看这里。
获取旧版微博直播弹幕
分析
我们在抓包的时候没有找到新版微博直播弹幕的标志,虽然我们仍可以找到这个直播的mid,但即便我们使用新版微博直播的api,也无法获得它的弹幕。
但是,我们可以发现微博在生成直播回放时,会把所有弹幕在评论中呈现,所以我们只需抓取所有的评论,即可得到当时的弹幕。这种方法同时适用于新旧版和一直播的弹幕获取,属于万能方法。
目前,微博为评论提供了新api和旧api,旧api只能精确到分钟,而新api可以精确到秒,因此这里我们采用新api,旧api的代码也一起放出(可能对于一些远古直播只能用旧api)
旧api(点击展开)
然而,评论中显示的时间只能精确到分钟,所以我们无法做到精确的还原弹幕出现的时间,因此我们只能做出妥协。
我的解决方法是,将每一分钟的弹幕平均分配到这一分钟,而不是同时出现,这样对于弹幕数量巨大的直播可以提高观看体验,而不用在每一分钟突然出现一堆弹幕。许多主播都会跟弹幕进行互动,如果主播念弹幕的时候,弹幕还没出现,这可能会对观众造成困惑,所以,我们将弹幕出现的瞬间往前移动,但不早于开播时间。
如果弹幕数量很少,你还可以尝试手动对齐弹幕的时间(会很累)。
如果你有更好的解决方法,欢迎与我交流。但是在此之前,请查看新api的解决方案,它可以精确到秒。如果没有抓到buildComment的包,只抓到aj/v6/comment/big的包,也可以把big?ajwvr的包后面的id用在新api中,或许也能正常使用。
首先我们需要获取直播的mid
以 [这次直播](https://weibo.com/l/wblive/p/show/1022:2321324610753620738144) 为例
F12-在Filter中输入comment-刷新网页,可以捕捉到这个包
新api:
https://weibo.com/ajax/statuses/buildComments?is_reload=1&id=4610753963230350&is_show_bulletin=2&is_mix=0&max_id=0&count=20&uid=5269600336
旧api:
https://weibo.com/aj/v6/comment/big?ajwvr=6&id=4610753963230350&filter=all&from=singleWeiBo
其中,id=4610753963230350,就是我们需要的。
我们可以从
https://weibo.com/aj/v6/comment/big?ajwvr=6&id=4610753963230350&filter=all&from=singleWeiBo获取评论
然后我们就会发现,获取到的内容实在太乱,我们把它的unicode翻译过来后,可以大概看出是一堆html标签,我们要做的就是把所有评论从这些html标签中剥离出来。
另外,它只能获取一页的评论,一页的评论只有15条。如果在评论区往下滑,可以加载下一页的评论。而下一页评论的获取方式就藏在上一页之中。
如果有下一页的评论,则会有root_comment_max_id,获取它的值,下一页的网址便是https://weibo.com/aj/v6/comment/big?ajwvr=6&id=4610753963230350&root_comment_max_id=$改为它的值$&root_comment_max_id_type=&root_comment_ext_param=&page=$页数*15$&filter=all&sum_comment_number=$页数+1$&filter_tips_before=0&from=singleWeiBo
下面给出代码
OldDanmuDownloader.java
public static void get(String filepath, String id, String start) throws Exception {
String url = "https://weibo.com/aj/v6/comment/big?ajwvr=6&id="+id+"&filter=all&from=singleWeiBo";
String origin = StringUtil.unicodeToCn(HttpUtil.sendGET(url));
List<DanMu> danMuList = new ArrayList<>();
//递归获取所有评论
next(origin, danMuList, id, 1);
//输出评论
for(DanMu danMu : danMuList){
System.out.println("{name="+danMu.name+", info="+danMu.info+", time="+danMu.time+"}");
}
long timeStamp = DanMuConverter.getTimeStamp(start);
//重设弹幕出现的时间
DanMuConverter.resetTime(danMuList, timeStamp);
//转换为xml文件
DanMuConverter.convertToXML(filepath, danMuList, timeStamp);
}
private static void next(String next, List<DanMu> danMuList, String id, int page) throws Exception {
String text = next;
String text2 = next;
System.out.println(text);
int index;
while ((index = text.indexOf("<img alt=\\\"")) != -1){
text = text.substring(index+11);
String name = text.substring(0, text.indexOf("\\\""));
text = text.substring(text.indexOf("<\\/a>:")+6);
String info = text.substring(0, text.indexOf("<\\/div>"));
while (!info.isEmpty() && info.endsWith(" ")){
info = info.substring(0, info.length()-1);
}
//将emoji从html标签抽离出来
info = DanMuConverter.replaceEmoji(info);
text = text.substring(text.indexOf("<div class=\\\"WB_from S_txt2\\\">")+30);
String time = text.substring(0, text.indexOf("<\\/div>"));
if(time.contains("月")){
time = calendar.get(Calendar.YEAR)+"-"+time.replace("月", "-").replace("日", "");
}
time += ":00";
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
Date date = simpleDateFormat.parse(time);
long ts = date.getTime();
danMuList.add(new DanMu(name, info, ts));
}
if(text2.contains("root_comment_max_id")) {
text2 = text2.substring(text2.indexOf("root_comment_max_id=") + 20);
String next2 = text2.substring(0, text2.indexOf("&"));
String nextURL = "https://weibo.com/aj/v6/comment/big?ajwvr=6&id="+id+
"&root_comment_max_id="+next2+
"&root_comment_max_id_type=&root_comment_ext_param=&page="+page * 15+
"&filter=all&sum_comment_number="+(page+1)+"&filter_tips_before=0&from=singleWeiBo";
String nextOrigin = StringUtil.unicodeToCn(HttpUtil.sendGET(nextURL));
next(nextOrigin, danMuList, id, page+1);
} else {
System.out.println("end");
}
}
重设时间 DanmuConventor.java
public static void resetTime(List<DanMu> list, long startTimeStamp){
//将所有时间段的弹幕(分钟)分开
Map<Long, List<DanMu>> map = new HashMap<>();
for(DanMu danMu : list){
if(map.containsKey(danMu.time)){
map.get(danMu.time).add(danMu);
} else {
List<DanMu> l = new ArrayList<>();
l.add(danMu);
map.put(danMu.time, l);
}
}
//将所有时间段的弹幕平均分配到各个分钟中
for(List<DanMu> l : map.values()){
//每个弹幕相隔的时间,最短1ms
long tick = Math.max(1, 60_000 / l.size());
for (int i = 0; i < l.size(); i++) {
l.get(i).time += tick * i;
}
}
//将所有弹幕提前一分钟,但不早于开播时间
for(DanMu danMu : list){
danMu.time = Math.max(startTimeStamp, danMu.time - 60_000);
}
}
执行方法示例
OldDanmuDownloader.get("D:/WeiboDanmuDownloader/danmu.xml","4632511801722334", "2021-5-2 20:59");
get()中有一个参数String start,你只要把微博显示的时间输入进去即可。
以上面说的视频为例,如果发布时间是今年,会显示为5月2日 20:59,否则显示为2021-5-2 20:59,这两种都会自动识别。注意它会影响弹幕出现的时间,执行完后请检查弹幕出现的时间是否正常,以决定是否要调整偏移。
新api
以 这次直播 为例。
F12-在Filter中输入comment-刷新网页-点击评论列表上的按时间,可以捕捉到这个包
https://weibo.com/ajax/statuses/buildComments?flow=1&is_reload=1&id=4603087451062716&is_show_bulletin=2&is_mix=0&max_id=0&count=20&uid=1912713353
其中,id 为本次直播的id,最后的 uid 是主播6岛岛的uid,我们可以通过 weibo.com/1912713353 访问他的微博空间。
count为本次获取的评论数量,如果把它改的大一些,可以一次获取更多弹幕。但经过实验,改大一些会导致只能获取部分弹幕,所以不改。
至于 max_id ,首先我们要知道我们滑到评论区的时候,并不会一次性加载所有评论,否则你的电脑会爆炸。微博会先加载一部分评论,当你继续往下滑,滑到底的时候,加载更多评论。而每加载一次评论,都会获取到一个 max_id ,而我们只需把上面网址中的 max_id 改为获取到的 max_id 的值可加载下一次评论,是不是有点链表的感觉了。直到 max_id 再次为0时,终止获取。
获取到的内容大概是这样:
{ok: 1, filter_group: [{param: "flow=0", scheme: "", title: "按热度", isDefault: 0},…],…}
data: [{created_at: "Sat Feb 13 02:16:38 +0800 2021", id: 4603963079133242, rootid: 4603963079133242,…},…]
filter_group: [{param: "flow=0", scheme: "", title: "按热度", isDefault: 0},…]
max_id: 4603115430486469 <--------------------注意这里
ok: 1
rootComment: []
total_number: 4530
trendsText: "已加载全部评论"细心的朋友会发现,获取到的内容还有一个 total_number ,似乎是评论的总数,但我们实际获取到的评论数量是小于这个数的,因为微博会自动吞掉一些评论(也就是我们在手机端看到的“已过滤不当言论,部分评论暂不展示”)。
明显,下一个max_id就是4603115430486469
也就是说,下一个包便是
https
不过呢,这样获取的弹幕会有不同步的问题,因为实际直播的时候可能会由于主播网络波动,而造成时间的损失,比如直播时间是17:00-18:00,在17:30的时候卡了一分钟,所以生成的回放只有59分钟。而弹幕不会因为这一分钟的卡顿丢失,所以会产生一分钟的弹幕偏移。
为此,我专门写了一个简单的程序,降低了手动修复弹幕时间的难度,在文末提供。
代码 OldDanmuDownloader.java
public static void get(String filepath, String id, String start) throws Exception{
List<DanMu> danMuList = new ArrayList<>();
//递归获取所有评论
next(danMuList, id, "0");
//输出所有评论
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
for(DanMu danmu : danMuList){
System.out.println(simpleDateFormat.format(new Date(danmu.time)) + " " + danmu.name + " : " + danmu.info);
}
long timeStamp = DanMuConverter.getTimeStamp(start);
//转换为xml文件
DanMuConverter.convertToXML(filepath, danMuList, timeStamp);
}
private static void next(List<DanMu> danMuList, String id, String max_id) throws Exception {
String url = "https://weibo.com/ajax/statuses/buildComments?flow=1&is_reload=1&id="+id+"&is_show_bulletin=2&is_mix=0&max_id="+max_id+"&count=20";
String origin = StringUtil.unicodeToCn(HttpUtil.sendGET(url));
// System.out.println(origin);
JSONObject root = new JSONObject(origin);
JSONArray array = root.getJSONArray("data");
for(Object obj : array){
if(obj instanceof JSONObject){
JSONObject danmuRaw = (JSONObject) obj;
long timestamp = new Date(danmuRaw.getString("created_at")).getTime();
String content = danmuRaw.getString("text");
//将emoji从html标签抽离出来
content = DanMuConverter.replaceEmoji(content);
JSONObject userJSON = danmuRaw.getJSONObject("user");
String user = userJSON.getString("name");
danMuList.add(new DanMu(user, content, timestamp));
}
total++;
}
if(t % 5 == 0){
Thread.sleep(3000);
}
t++;
System.out.println("total: "+total);
if (root.has("max_id")) {
if (root.getLong("max_id") != 0) {
String next_max_id = String.valueOf(root.getLong("max_id"));
next(danMuList, id, next_max_id);
} else {
System.out.println("last_max_id: " + max_id);
Thread.sleep(3000);
//再次确认(因为有时候会抽风)
origin = StringUtil.unicodeToCn(HttpUtil.sendGET(url));
root = new JSONObject(origin);
if (root.has("max_id") && root.getLong("max_id") != 0) {
String next_max_id = String.valueOf(root.getLong("max_id"));
next(danMuList, id, next_max_id);
} else {
System.out.println("end");
}
}
}
}
DanmuConventor.java
public static long getTimeStamp(String start) throws Exception{
if(start.contains("月")){
start = calendar.get(Calendar.YEAR)+"-"+start.replace("月", "-").replace("日", "");
}
start += ":00";
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
Date date = simpleDateFormat.parse(start);
return date.getTime();
}
get()中有一个参数String start,你只要把微博显示的时间输入进去即可。
以上面说的视频为例,如果发布时间是今年,会显示为5月2日 20:59,否则显示为2021-5-2 20:59,这两种都会自动识别。注意它会影响弹幕出现的时间,执行完后请检查弹幕出现的时间是否正常,以决定是否要调整偏移。
获取“一直播”弹幕
分析
“一直播”也有实时弹幕的api,虽然只能精确到秒,但这也足够了。
不过呢,“一直播”的弹幕会有不同步的问题,因为实际直播的时候可能会由于主播网络波动,而造成时间的损失,比如直播时间是17:00-18:00,在17:30的时候卡了一分钟,所以生成的回放只有59分钟。而弹幕不会因为这一分钟的卡顿丢失,所以会产生一分钟的弹幕偏移。
为此,我专门写了一个简单的程序,降低了手动修复弹幕时间的难度,在文末提供。
以 https://www.yizhibo.com/l/HVuil7Qy-rrfTvjl.html 为例
当然,这次直播的回放已经播放不了了,不过还能获取到弹幕。但是 LHAxx 大佬保存了这一次的直播回放,你可以在 这里 观看。你可以通过 这个网站 来下载这个的视频。
“一直播”的弹幕获取从https://www.yizhibo.com/live/h5api/get_playback_event?scid=HVuil7Qy-rrfTvjl&ts=0获取。
其中,scid表示是哪一次直播,这个可以直接从上面举例的网址中获得,即HVuil7Qy-rrfTvjl。
ts表示获取哪一个时间段的弹幕。不过,它一次只能获取一部分弹幕,可能是30条,可能是25条,也可能是21条,总之不确定。它也不像新版微博弹幕那样每30s分为一段,下一段弹幕的时间段可能是30s,也可能是17s。而下一个ts的值为上一个弹幕内容中最大一个+1,直到获取不到为止。
获取到的信息部分内容:
...
list: [
{id: 1240933322104635400, did: 0, type: 0, ts: 9000, memberid: "57269095", content: "来啦",…},
{id: 1240933326265385000, did: 0, type: 0, ts: 10000, memberid: "74194355", content: "来啦",…}
...思路和新版微博弹幕相同。
代码
NewDanmuDownloader.java
public static void get(String filepath, String scid, long startTimeStamp){
try {
List<DanMu> result = new ArrayList<>();
next(scid, startTimeStamp, 0, result);
//保存弹幕文件
DanMuConverter.convertToXML(filepath, result, startTimeStamp);
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
for(DanMu danmu : result){
System.out.println(simpleDateFormat.format(new Date(danmu.time)) + " " + danmu.name + " : " + danmu.info);
}
} catch (Exception e) {
e.printStackTrace();
}
}
public static void next(String scid, long startTimeStamp, long ts, List<DanMu> list) throws Exception {
String url = "https://www.yizhibo.com/live/h5api/get_playback_event?scid="+scid+"&ts=55001"+ts;
String origin = HttpUtil.sendGET(url);
System.out.println(origin);
JSONObject root = new JSONObject(origin);
JSONObject data = root.getJSONObject("data");
JSONArray array = data.getJSONArray("list");
if(array.length() > 0) {
long maxTs = 0;
for (Object entry : array) {
if (entry instanceof JSONObject) {
JSONObject danmuRaw = (JSONObject) entry;
//获取弹幕发送者名称,实际渲染的时候不包含发送者名称
//如果没有nickname,则直接将其id作为名称
//一直播的nickname可能为null,所以还需判断是否为null
String name;
if (danmuRaw.has("nickname") && !danmuRaw.isNull("nickname")) {
name = unicodeToCn(danmuRaw.getString("nickname"));
} else {
name = String.valueOf(danmuRaw.getLong("id"));
}
//弹幕的时间
long dTs = danmuRaw.getInt("ts");
maxTs = Math.max(maxTs, dTs);
String content = unicodeToCn(danmuRaw.getString("content"));
//将emoji从html标签抽离出来
content = replaceEmoji(content);
DanMu danmu = new DanMu(name, content, startTimeStamp + dTs);
list.add(danmu);
}
}
next(scid, startTimeStamp, maxTs + 1L, list);
} else {
//超过10分钟没有弹幕,停止收集
//防止一段时间内没人发弹幕而获取不完整
if(noDanmuTick >= 60){
return;
}
noDanmuTick++;
next(scid, startTimeStamp, ts + 10001L, list);
}
}
处理弹幕中的emoji
以该弹幕内容为例
哈哈哈<img src=\"//face.t.sinajs.cn/t4/appstyle/expression/ext/normal/83/2018new_kuxiao_org.png\" title=\"[允悲]\" alt=\"[允悲]\" /><img src=\"//face.t.sinajs.cn/t4/appstyle/expression/ext/normal/83/2018new_kuxiao_org.png\" title=\"[允悲]\" alt=\"[允悲]\" />哈哈哈如果我们把这一大串内容渲染到弹幕中那将会对观感造成灾难性的破坏。我们可以选择忽略掉该弹幕,或者将该弹幕中的emoji去掉,但这两种方法都会造成信息缺失。
我们发现,在emoji中有一个title,如果我们只显示title中的内容,这样既不丢失内容,也不对观感造成太大影响,是一个不错的选择。
效果如下
哈哈哈[允悲][允悲]哈哈哈
另外,弹幕中可能会出现@的内容,大概长这样
<a href="https://weibo.com/u/7392553055">@LSeng</a>我们也需要把它提取出来。
代码如下
public static String replaceEmoji(String content){
while (content.contains("<img") || content.contains(">a")){
int indexImg = content.indexOf("<img");
int indexA = content.indexOf("<a");
if(indexImg != -1 && indexA == -1){
//只包含Emoji
content = replaceFrontImg(content);
} else if (indexImg == -1 && indexA != -1){
//只包含@
content = replaceFrontAt(content);
} else {
//既包含Emoji又包含@
if(indexImg < indexA){
//Emoji在前面
content = replaceFrontImg(content);
} else {
//@在前面
content = replaceFrontAt(content);
}
}
}
return content;
}
private static String replaceFrontImg(String content){
String bad = content.substring(content.indexOf("<img"), content.indexOf("/>")+2);
if(bad.contains("title=\"")){
String sec = bad.substring(bad.indexOf("title=\"")+7);
String emojiStr = sec.substring(0, sec.indexOf("\""));
content = content.replace(bad, emojiStr);
} else if(bad.contains("title=\\\"")){
String sec = bad.substring(bad.indexOf("title=\\\"")+8);
System.out.println(sec);
String emojiStr = sec.substring(0, sec.indexOf("\\\""));
content = content.replace(bad, emojiStr);
} else {
content = content.replace(bad, "");
}
return content;
}
private static String replaceFrontAt(String content){
while (content.contains("<a")) {
String bad = content.substring(content.indexOf("<a"), content.indexOf("/>") + 2);
if(bad.contains("@")) {
String at = bad.substring(bad.indexOf(">") + 1, bad.indexOf("</a>"));
content = content.replace(bad, at);
} else {
content = content.replace(bad, "");
}
}
return content;
}
如果能将emoji的图片渲染进弹幕里就好了。
事实上,这是可行的,但它超过了我的能力范围。如果你有解决方案,欢迎与我交流。
毕竟,下面才应该是最佳的显示效果

将弹幕渲染到视频中
渲染是一个很复杂的过程,但我们无需重复造轮子,利用现有的工具,即可快速完成对弹幕的渲染。
SSA/ASS是众多字幕制作者常用的字幕格式,它非常强大,不仅可以制作一般的文本字幕,还能制作非常好看的特效字幕,甚至绘制图形。
为了显示出更好的弹幕效果,我们需要保证不同长度的弹幕有不同的运动速度,而且在正确的位置上显示而不遮挡其他弹幕。特别是滚动弹幕,在尽量靠上的位置出现。这似乎是一道数学题,不过不用担心,因为已经有人帮我们做好了一个工具。
niconvert是一个强大的弹幕转化工具,它主要用于将bilibili的xml格式弹幕文件转化为ass字幕文件。不过,为了使用该工具,你需要下载并安装 Python。
b站的弹幕文件大概长这样
<?xml version="1.0" encoding="utf-8"?>
<?xml-stylesheet type="text/xsl" href="#s"?>
<i>
<d p="113.64,1,25,16777215,1643697207000,0,16467437,0" user="Kar-LSeng">哈哈哈</d>
<d p="118.08,1,25,16777215,1643697207000,0,16467437,0" user="Kar-LSeng">笑死我了</d>
</i>其中p=后面的一堆数字,分别代表(如果显示不出来请尝试刷新网页)
$$\underbrace{113.64}_{\mathrm{弹幕出现时间}},\overbrace{1}^{\mathrm{弹幕模式}},\underbrace{25}_{\mathrm{弹幕字号}},\overbrace{16777215}^{\mathrm{字体颜色}},\underbrace{1643697207000}_{\mathrm{时间戳}},\overbrace{0}^{\mathrm{弹幕池}},\underbrace{16467437}_{\mathrm{发送者uid}},\overbrace{0}^{\mathrm{rowID}}$$
- 弹幕出现时间,指弹幕在视频中出现的时间,单位为秒,可以使用小数。
- 弹幕模式,1-3 滚动弹幕,4 底端弹幕,5顶端弹幕,6 逆向弹幕,7 精准定位,8 高级弹幕。
- 弹幕字号 (12非常小,16特小,18小,25中,36大,45很大,64特别大)
- 字体颜色,十进制,16777215的十六进制是ffffff,也就是白色。
- 时间戳,指Unix格式的时间戳。基准时间为 1970-1-1 08:00:00。
- 弹幕池,0普通池 1字幕池 2特殊池
- 发送者uid,可以通过space.bilibili.com/uid访问该用户的空间
- 弹幕在数据库中的rowID,b站的视频中当弹幕过多时,只会显示最新的一部分弹幕,这个rowID的作用可以用来根据发布时间排序。
来源:http://9ch.co/t17836,1-3.html
我们只需模仿这个格式,即可使用该工具对弹幕进行转化。
由于我们要转化的是微博的弹幕,所以我们只需要用到其中一部分就行,另外的几个参数可以随便填。
代码
DanMuConverter.java
private static void writeIntoFile(String filePath, String info){
String filePath2 = filePath.replace("\\", "/");
int index = filePath2.lastIndexOf("/");
String dir = filePath2.substring(0, index);
File fileDir = new File(dir);
fileDir.mkdirs();
File file = new File(filePath);
try {
if(!file.exists()) {
file.createNewFile();
}
try(FileWriter fileWriter = new FileWriter(file)) {
fileWriter.write(info);
fileWriter.flush();
} catch (IOException e){
e.printStackTrace();
}
} catch (IOException e) {
e.printStackTrace();
}
}
public static void convertToXML(String filePath, List list, long start) throws Exception {
File file = new File(filePath);
if(file.exists()){
file.delete();
}
writeIntoFile(filePath, "<?xml version=\"1.0\" encoding=\"utf-8\"?>\n" +
"<?xml-stylesheet type=\"text/xsl\" href=\"#s\"?>\n" +
"<i>\n");
for (int i = list.size() - 1; i >= 0; i--) {
DanMu danMu = list.get(i);
String second = String.valueOf((danMu.time - start) / 1000);
String result = " <d p=\"" + second + ",1,25,16777215," + danMu.time + ",0,1602022773,0\" user=\"" + danMu.name + "\">" + danMu.info + "</d>\n";
writeIntoFile(filePath, result);
}
writeIntoFile(filePath, "</i>");
}
接着就可以回到上面get(...)方法中去掉DanMuConverter.convert(...);的注释了
当然,对于 niconvert,其实可以不用转化为xml,你也可以转化为json格式,参见https://github.com/muzuiget/niconvert/blob/master/docs/json.md,但是,经过我的实验,json格式的转换似乎有问题,如果使用json,需要保证json中start的顺序为从小到大,否则无法正常显示。我已经向作者提交了 issues。因此我们暂时使用xml。
另外在使用json的时候,点击 输入文件 后的浏览按钮,需要把右下角的文件类型从 XML 文件(*.xml)改为JSON 文件(*.json),你才能找到json文件。
转化为json的代码(点击展开)
public static void convertToJSON(String filePath, List<DanMu> list, long start) {
File file = new File(filePath);
if(file.exists()){
file.delete();
}
JSONArray array = new JSONArray();
for (int i = 0; i < list.size(); i++) {
JSONObject obj = new JSONObject();
DanMu danMu = list.get(i);
obj.put("start", (danMu.time - start) / 1000);
obj.put("style", "scroll");
obj.put("color", "ffffff");
obj.put("commenter", danMu.name);
obj.put("content", danMu.info);
obj.put("is_guest", false);
array.put(obj);
}
writeIntoFile(filePath, array.toString(Main.indent ? 4 : 0));
}
使用niconvert
下载并解压niconvert后,运行main.pyw,如果无法运行,可能是你未安装 Python。
软件的界面大概长这样

输入输出
点击输入文件后的浏览按钮,找到将上述生成的文件。这时候输出文件会自动填充。但请注意浏览第二个文件之后,输出文件可能不会自动修改,请记得修改输出文件。
我曾犯下的错误:
- 在浏览第二个文件之后,没有修改输出文件,导致第一个输出文件被覆盖。
- 在浏览第二个文件之后,直接复制输入文件的地址到输出文件中,忘记修改后缀名,导致输出文件覆盖输入文件。
弹幕选项
过滤文件用于过滤弹幕内容。你可以创建一个文本文档,每一行正则表达式匹配,如
最后
结局
^剧透
是凶手$
表达式使用部分匹配,简单的关键词直接打上即可。
如果要使用完全匹配,可以和 ^ 或 $ 配搭使用。
参见这里
在b站的直播中,通常会有人送节奏风暴礼物或者抽奖、红包等,他们会产生大量的垃圾弹幕,你可以用这个功能去除这些弹幕。
另外三个选项在微博弹幕中用不到,直接跳过。
字幕选项
分辨率无需和原视频一样,只需比例相同即可,比如横屏的1280x720你可以选择1920x1080;竖屏的720x1280你可以选择1080x1920,后面再解释为什么。
字体名称,微软雅黑其实就很好看,但如果你有商业用途请注意字体版权。
字体大小,对于1080p,如果是横屏的话,80像素在手机上显示效果不错,在较小的(如23英寸)电脑显示器上也可以接受,但是在大屏上会显得过大,所以你可以另外再生成一个40像素的,以便提高在大屏的观看体验(记得修改输出文件名称)。如果是竖屏,80像素在手机和电脑显示器都有不错的效果,除非你将电脑显示器调为竖屏显示(别惊讶,程序员经常这么干,因为很多程序员喜欢竖屏写代码)。
限制行数,如果弹幕的数量过多,需要占用更多的行数,会丢弃超出行数的弹幕。我一般调为9999,不过如果弹幕太多超出了屏幕范围还是会导致信息丢失。
布局算法,速度同步是每一条弹幕速度都相同,而速度异步是弹幕的速度会根据它的长度调整,长度越大速度越快。一般选择速度异步,弹幕的总体速度会很快,特别是对于横屏,在电脑显示器上滚动过快看不清,所以需要调整下面的微调时长选项。
微调时长,如果感觉弹幕过快或过慢,可以调整该选项。正数变慢,负数变快。
自定偏移,如果弹幕出现的时间过早或过晚,可以修改该选项,负数代表往前偏移,正数代表往后偏移。
详细的配置说明请看 niconvert 文档
如果你觉得这样过于麻烦,也可以直接使用我写的 弹幕时间调节器,它内置了 niconvert ,可以用于修复弹幕不同步的问题,并自动生成ass文件。
渲染
终于到了最后一步了,接下来我们可以将生成的ass文件渲染到视频中。
且慢,渲染前请检查弹幕的大小、速度、出现的时间等是否正确。
你可以使用任意支持ass字幕的播放器,它会在播放视频的时候检查与该视频同一目录下是否有同名的ass文件,你也可以在播放视频的时候将ass文件拖入播放器来加载该文件。potplayer 是一个不错的选择。不过它的官网在中国好像上不去,你也可以选择我的镜像:
接着,我们便可以将弹幕渲染进视频中了。你可以使用任何支持将弹幕和视频渲染在一起的软件进行渲染。
这里我们使用 ffmpeg,它是一个命令行的工具,所以需要输入指令来使用。请注意官网提供的是源代码的下载,我们需要的是 Windows 的可执行文件。
下载方法和环境变量的设置可以看 这篇文章,我们没有在用Captura,所以第三步就不用看了。
在设置环境变量的时候请小心,不要删除了其他的环境变量,否则可能会让你的系统出现异常。
接着,按win+r,输入cmd,回车以打开命令提示符,然后在命令提示符中输入ffmpeg -version,即可检查你在上面的操作是否正确。
然后将需要渲染的视频和ass文件放在同一个目录下,接着点击图下位置,它便可以变成文本输入框,将里面的内容改为cmd然后回车,就可以在当前目录下打开命令提示符。

在命令提示符中输入
ffmpeg -i 视频 -c:v h264_nvenc -profile:v main -b:v 5824k -vf ass=弹幕文件 输出文件
回车,即可渲染视频,注意后缀名。
比如ffmpeg -i video.mp4 -c:v h264_nvenc -profile:v main -b:v 5824k -vf ass=danmu.ass output.mp4
注意,如果你的显卡不是 NVIDIA 显卡,请把上面的 h264_nvenc 改为 h264 。
-b:v 后的参数是码率,如果你要上传到b站的话,靠近但低于6000kbps的码率可以既保证质量又不会被二压。请注意b站网页端最大支持8GB(电磁力达到一定等级后32GB),最长10个小时的视频。
但是,我们会发现,如果原视频文件的分辨率过低的话,渲染出来的视频中弹幕会过于模糊。如果原视频文件的帧数过低的话,渲染出来的视频中弹幕会很卡。因此,我们需要对原文件做处理后再渲染。
我们可以在该目录下创建一个文本文件,并输入
ffmpeg -i video.mp4 -c:v h264_nvenc -profile:v main -b:v 5824k -vf scale=1920x1080 -r 60 video_hq.mp4
ffmpeg -i video_hq.mp4 -c:v h264_nvenc -profile:v main -b:v 5824k -vf ass=danmu.ass output.mp4请按照实际情况修改其中的文件名。
保存后,将文本文件的后缀名改为cmd,运行它,这样就可以渲染出高质量的视频了。
请注意,scale后面的1920x1080是16:9的(横屏),如果是9:16的(竖屏),则需要改为1080x1920。如果是其他比例,按比例扩大其分辨率即可。
注意你的磁盘空间,生成的文件可能会很大。 比如1小时的视频,按上面步骤生成的两个文件加起来会有5GB。
渲染完成后,即可删除 video_hq.mp4 文件。
我们可以发现,这个过程经过了两遍渲染,需要的时间会比较长,占用空间也大。如果你有一遍渲染就可以解决的方法,可以与我交流。
资源下载
后记
6岛岛 是我最喜欢的萌宠博主之一,他在微博上的众多直播回放质量都很高,让我反复回味。
2016年5月24日,6岛岛 发布了与9鹅在户外的一次直播回放,也是我最喜欢的作品之一。
2022年2月3日,正当我准备将那些记忆保存下来时,才发现为时已晚。6岛岛几乎所有的微博直播回放,都已经无法播放。我尝试了许多方法,企图挽回这些记忆,最终都是徒劳一场。问了客服,才知道系统升级后,超过一年的直播回放已经不会保存了。不仅仅是直播回放,许多视频只剩下一行冷冰冰的“抱歉,该视频无法播放”。我本以为以微博这样一个大平台会保留我们记忆很长一段时间,最后才发现,那些记忆早已被无情抹去,互联网的记忆是有限的。
如果你有保存,或者找到6岛岛在2016-2018年的直播回放,请与我联系,我可以有偿获取。
b站私信:https://message.bilibili.com/?spm_id_from=333.999.0.0#/whisper/mid16467437
感谢LHAxx大佬保存了6岛岛在2019年和2020年的直播回放,也算是挽回了一部分记忆。
2022年2月7日,我尝试查看6岛岛的2016年5月23日的直播回放资源,即index.m3u8时,发现返回了InvalidObjectState。根据6岛岛的这个微博,这场直播持续了两个多小时。在我的测试下,我发现直到868.ts,返回的都是InvalidObjectState,而在访问869.ts时,返回了NoSuchKey。1个ts文件大概是10秒钟,868个大概是2小时40分钟。微博使用的是阿里云的oss服务,根据阿里云oss服务关于403错误的文档最后一条的描述,下载归档类型Object时会出现InvalidObjectState错误,也就是说微博有可能只是将数据归档储存起来了,不一定删除了数据。还有希望,但如何才能让微博解冻这些数据呢?
2022年7月4日,上述链接返回404,也许已经永久删除了。































